MPEG Audio Layer-3

1987 begann das Frauenhoferinstitut für integrierte Schaltkreise (IIS) im
Rahmen eines europäischen Forschungsprojekts mit der Entwicklung eines
Kodierungsverfahrens für Digital Audio Broadcasting (DAB). Daraus entstand in
Zusammenarbeit mit der Universität Erlangen der standardisierte Algorithmus
ISO-MPEG Audio Layer-3 (IS 11172-3 and IS 13818-3).
Typische Audiosignale bestehen aus 16 Bit Auflösung, welche mit der
doppelten Audiobandbreite (ca. 44,1 kHz bei Compact Disks) aufgenommen werden.
Für jede Sekunde Stereomusik in CD-Qualität benötigt man daher ca.
1,4 MBit. Durch das Verfahren MPEG Audio Layer-3 lässt sich diese
Datenmenge um den Faktor 12 reduzieren, ohne an Qualität zu verlieren. Darüber
hinaus lassen sich selbst mit Reduktionsfaktoren von 24 und mehr Qualitäten
erreichen, die besser sind als jene, die man durch Reduktion der Auflösung und
Aufnahmerate erhalten würde. Dieses wird im Prinzip vor allem durch die
Berücksichtigung der physiologischen Eigenschaften des menschlichen Gehörs erreicht.
Durch das Verfahren MPEG Audio Layer-3 lässt sich die typische Datenmenge
bei Erhaltung der originalen CD-Klangqualität reduzieren auf
In sämtlichen internationalen Hörtests stellte MPEG Audio Layer-3 seine
überlegene Leistung unter Beweis, wobei die originale Klangqualität bei einer
Datenreduktion von 1 zu 12 erhalten blieb (ca. 64 kBit/s). Bei einer
Beschränkung der Bandbreite auf 10 kHz lässt sich eine vernünftige
Klangqualität für Stereosignale auch bei einer Reduktion von 1 zu 24
erreichen. Von der ITU-R wird MPEG Audio Layer-3 für Rundfunksendungen bei
einer Bitrate von 60 kBit/s pro Audiokanal empfohlen. (ITU-R doc. BS.1115)
Details
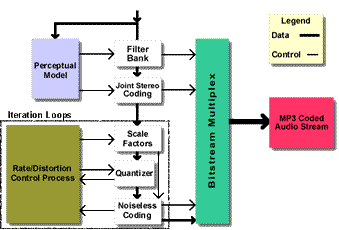 Filterbank
Filterbank
Die im MPEG Audio Layer-3 verwendete Filterbank ist eine
Hybridfilterbank, die aus einem Polyphasenfilterbank und einer modifizierten
Cosinus-Tranformation (MDCT) besteht. Diese Hybridform wurde aus Gründen der
Kompatibilität mit den Vorgänger-Codecs Layer-1 und Layer-2 gewählt.
Wahrnehmungsmodell
Das Wahrnehmungsmodell bestimmt hauptsächlich die Qualität
einer Encoder-Implementierung. Es benutzt entweder eine separate Filterbank oder
es kombiniert die Berechnung aus Energiewerten (zur Maskierungsberechung) mit
der Hauptfilterbank. Die Ausgabe des Wahrnehmungsmodells besteht aus Werten für
die Schwellwerte zur Maskierung oder den erlaubten Geräuschpegelabstand für
jede Coder-Partition. Wenn das Quantisierungsgeräusch unter den
Maskierungsschwellwerten gehalten werden kann, sollten die
Kompressionsergebnisse vom Originalsignal nicht mehr unterschieden werden
können.
Joint Stereo
Gemeinsame Stereokodierung nutzt aus, dass beide Stereokanäle
nahezu die gleiche Information enthalten. Aus diesen stereophonen
Unwesentlichkeiten und Redundanzen kann die totale Bitrate reduziert werden.
Gemeinsame Stereokodierung wird eingesetzt, wenn bei geringen Bitraten
Stereosignale erwünscht sind.
Quantizierung und Kodierung
Ein System zweier verschachtelter Schleifen ist der grundlegende
Lösungsansatz zur Quantisierung und Kodierung beim Layer-3-Encoder.
Quantisierung wird mittels eines Potenz-Quantisierer durchgeführt, so dass
große Werte automatisch weniger genau kodiert werden, bei gleichzeitiger
Geräuschreduktion. Die quantifizierten Werte werden mit der verlustlosen
Huffman-Kodierung behandelt, so dass dem Audisignal keine zusätzliches
Störsignal hinzugefügt wird.
Um die optimalen Schranken und Skalierungsfaktoren bei gegebenem
Block, Bitrate und Ausgabe des Wahrnehmungsmodells zu finden, werde in der Regel
zwei verschachtelte Schleifen in einem Analysis-Syntheseverfahren verwendet:
Innere Iteratiosschleife
Die Huffman-Kodierungstabelle weist den häufiger auftretenden
kleineren Quantisierungswerten kürzere Codewörter zu. Sollte die Anzahl der in
einem Datenblock verfügbaren Bits die vorgegebene Grenze überschreiten, so
können durch Veränderung der Schwellwerte die Quantisierungsschritte erhöht
werden, bis die erforderliche Bitrate klein genug ist. Diese Schleife wird auch
als "Rate-Schleife" bezeichnet, da sie die gesamte Coder-Rate
reduziert, bis sie klein genug ist.
Äußere Iterationsschleife (Störgeräuschkontrolle /
Verzerrung)
Damit das Quantisierungsgeräusch entsprechend der
Maskierungsgrenze beschränkt wird, werden Skalierungsfaktoren auf jedes
Skalierungsfaktorband angewendet. Das System beginnt mit einem Defaultwert von
1,0. Ist das Quantisierungsgeräusch (d.h. der zulässige Geräuschpegel)
größer als die Maskierungsgrenze, wie sie vom Wahrnehmungsmodell vorgegeben
ist, wird der Skalierungsfaktor für dieses Band angepasst, um das
Quantisierungsgeräusch zu vermindern. Da eine feinere Quantisierung eine
größere Anzahl von Quantisierungsstufen und somit eine größere Bitrate
benötigt, muss die innere Iterationsschleife jedes Mal wiederholt werden,
wenn die Skalierungsfaktoren verändert werden; die innere Schleife ist also in
die äußere zu verschachteln. Die äußere Schleife zur Störgeräuschkontrolle
wird so oft wiederholt, bis das tatsächliche Störgeräusch (als Differenz aus
dem originalen Spektralwert minus dem quantisierten Spektralwert) unterhalb der
Maskierungsgrenze für jedes Skalierungsfaktorband ist (dem kritischen Band).
(Quelle: http://www.iis.fhg.de/amm/techinf/layer3/index.html)