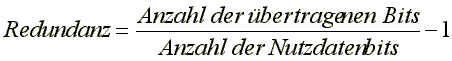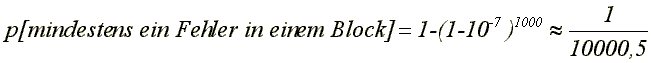Rechnernetze
![]()
![]()
|
Rechnernetze |
Fehlerentdeckung durch Redundanz
Liegt der Fehler in der Größenordnung von 10-, so tritt in den verbreiteten Ethernet-Systemen im Mittel in jeder Sekunde ein Fehler auf. Dieses ist ein für praktische Anwendungen viel zu großer Wert, da dieses bedeutet, dass in fast jeder übertragenen Datei ein fehlerhaftes Bit vorliegt. Werden Dateien mehrfach hin und her geschickt, so kann sich die Anzahl der Fehler schnell vergrößern. Aus diesem Grunde sind Übertragungsfehler unbedingt zu erkennen und zu korrigieren. Die wichtigsten Verfahren zur Fehlererkennung fassen mehrere Bits in Blöcke zusammen und fügen jedem Block ein oder mehrere Kontrollbits hinzu. Dieses bedeutet, dass die Anzahl übertragener Bits größer ist als die Anzahl von Bits, die Nutzinformation enthalten. Um dieses zu quantifizieren, führt man den Begriff der Redundanz ein; wir definieren hier die Redundanz als die relative zusätzliche Information, die zur Fehlererkennung verwendet wird: In der Literatur (insbesondere der Informationstheorie) findet man auch etwas andere Definitionen für die Redundanz! Sobald ein Fehler entdeckt wurde, muss der Fehler korrigiert werden. Dafür gibt es prinzipiell mindestens zwei Verfahren:
Das erste Verfahren wird auch ARQ genannt (automatic repeat request). Es ist bei weitem die am häufigsten angewendete Methode zur Fehlerkorrektur bei der Datenübertragung, da es in diesem Bereich ökonomischer ist als die zweite Methode. Beim ARQ-Verfahren werden korrekte bzw. falsche Blöcke durch eine Quittung (acknowledge; ACK) bzw. Not Acknowledge (NAK) bestätigt. Sollten ganze Blöcke verloren gehen, was auch geschehen kann, so sind besondere Vereinbarungen zu treffen, um die dadurch entstehenden Fehler zu beheben. Dieses wird z.B. im X.25-Protokoll auf der Bitsicherungsschicht angewendet (HDLC-LAPB) und dort genauer besprochen. In anderen Bereichen, z.B. bei der Speicherung von Daten, ist das ARQ-Verfahren jedoch nicht immer anwendbar, da dieses eine intensive Zusammenarbeit zwischen Sender und Empfänger einer Nachricht voraussetzt. Bei fehlerkorrigierenden Verfahren wird die Redundanz so groß gewählt, dass bei wenigen Fehlern aus der fehlerbehafteten Information die korrekte Information erschlossen werden kann. Zwar lassen sich im Prinzip beliebig viele Fehler korrigieren, was aber nur mit sehr großer Redundanz möglich ist. Aus diesem Grunde werden solche Verfahren bei der Datenübertragung nur eingesetzt, wenn die Fehlerwahrscheinlichkeit sehr hoch ist, z.B. bei der drahtlosen Datenkommunikation (Bluetooth™). In anderen Anwendungen (z.B. bei der CD-Kodierung) sind die Methoden dennoch sehr wichtig. Die folgenden Beispiele stellen zwei einfache und naheliegende Verfahren vor, die Fehler mit großer Wahrscheinlichkeit erkennen und sogar korrigieren können, wobei sie aber zugleich eine sehr große Redundanz besitzen. Eine sehr einfache Fehlererkennungsmethode besteht darin, alle Blöcke zweimal zu senden: Tritt ein Fehler auf, so sind die Blöcke unterschiedlich, und der Fehler kann somit erkannt werden. Wir nehmen an, dass die Fehlerwahrscheinlichkeit für ein einzelnes Bit 10-7 beträgt und die Blocklänge 1000 Bits; die Wahrscheinlichkeit, dass in einem Block (mindestens) ein Fehler auftritt, ist dann Bei diesem Verfahren muss daher ungefähr jeder zehntausendste Block zweimal gesendet werden, d.h. die Menge zu übertragender Information erhöht sich um einen Block je 10.000 Nutzdatenblöcken. Die Redundanz ist daher: Dieses bedeutet, dass die zu übertragende Information etwa doppelt so groß ist wie die Nutzinformation; das ist ein sehr hoher Wert. Um einen fehlerhaften Block unmittelbar korrigieren zu können, kann jeder Block dreimal geschickt werden. Sind in den drei Blöcken einige Bits falsch, so wird jener Wert genommen, der mehrheitlich vorhanden ist; man nennt dieses auch ein Entscheider- oder Schiedsrichterverfahren (arbiter). Die Redundanz ist ungefähr 2, also praktisch doppelt so hoch wie im ersten Fall. In diesen Beispielen erscheint die Redundanz in beiden Fällen sehr hoch; sie beträgt zwischen 100% und 200%. Zwar ist die Redundanz für die Kosten eines Verfahrens eine wichtige Kennzahl, dennoch sind auch andere Merkmale eines solchen Verfahrens für dessen Bewertung von Interesse, z.B.:
Die Wahrscheinlichkeit eines unerkannten Fehlers ist in beiden Fällen sehr gering. Tatsächlich wird im ersten Beispiel nur dann ein Fehler unentdeckt bleiben, wenn zwei Bits an der gleichen Stelle in beiden Blöcken falsch sind. Dieses tritt mit einer Wahrscheinlichkeit in der Größenordnung von 10-7000 auf, ist also praktisch ausgeschlossen. Im zweiten Beispiel liegen die Größenordnungen ähnlich. Zwar sind dieses sehr sichere Verfahren, aber der Nutzen steht hier nur in einem sehr schlechten Verhältnis zum Aufwand, da die Übertragungskapazität einer Leitung nur sehr schlecht ausgenutzt wird; man muss entweder eine schnellere Leitung verwenden, die entsprechend teurer ist, oder man muss eine größere Übertragungszeit in Kauf nehmen. Eingesetzt werden diese Verfahren bei dem drahtlosen Übertragungsstandard Bluetooth, der Ende der neunziger Jahre vorgestellt wurde und von jedem unentgeltlich genutzt werden kann. Hier wird zwischen synchronen Daten, die eine möglichst geringe Übertragungszeitschwankung besitzen sollen, und asynchronen Daten unterschieden. Die synchronen Daten werden nicht mit dem oben erwähnten ARQ-Verfahren gesichert, sondern ausschließlich mit fehlerkorrigierenden Verfahren, die dort forward error correction (FEC) genannt werden. Neben dem dreifachen Senden jedes Bits wird noch ein anderes Verfahren mit CRC-Kodierung benutzt, das später erläutert wird. Daneben wird auch Kontrollinformation entsprechend abgesichert. Soll dieses Problem ingenieurmäßig behandelt werden, so müsste prinzipiell zunächst eine erträgliche Fehlerwahrscheinlichkeit vorgegeben, und dann ein effizientes Verfahren zur Fehlererkennung konstruiert werden, welches mit möglichst geringen Kosten die geforderte Fehlerwahrscheinlichkeit einhält. Solche Verfahren werden bei der Paritätsprüfung betrachtet. |