Rechnernetze
![]()
![]()
|
Rechnernetze |
Huffmann-Kodierung
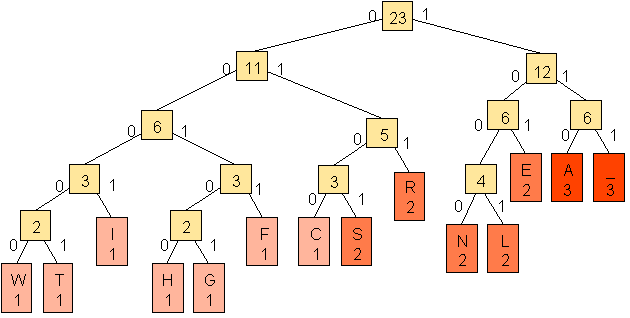
Die einfache Huffmann-Kodierung stellt eine algorithmische Umsetzung der informationstheoretischen Regel dar, möglichst gleichwahrscheinliche Teilmengen der zu kodierenden Werte zu verwenden, um eine (sub-) optimale Kodierung zu erhalten. Sie erzeugt einen binären Baum, dessen Blätter den Zeichen entsprechen, und der zu jedem Knoten zwei Nachfolger (0, 1) besitzt. Eine Kodierung verwendet jeweils ein entsprechendes Anfangsstück. Ein Algorithmus zur Huffmankodierung könnte folgendermaßen aussehen: 1. Initialisierung: Alle Zeichen werden Knoten zugeordnet und nach ihrer Häufigkeit in einer Liste sortiert. 2. Solange die Liste der Knoten noch mehr als ein Element enthält:
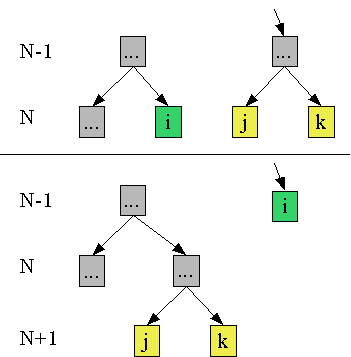
Im obigen Beispiel werden 86 Bits zur Kodierung des Textes "ALLER ANFANG IST SCHWER" benutzt, während eine Kodierung der 14 verschiedenen Zeichen mit jeweils 4 Bits 23*4=92 Bits benötigen würde. Die ideelle Entropie ist 3,6753, während die wahre Entropie in diesem Beispiel 86/23 = 3,739 ist, also nahe an der ideellen Entropie liegt. Grundsätzlich stellt sich die Frage, ob die Huffman-Kodierung jeweils eine bessere Kodierung ergibt als eine Kodierung mit Hilfe gleichlanger Wörter. Die Antwort ist überraschenderweise ja, solange die absolute Häufigkeit der einzelnen Zeichen bekannt ist. Man kann sich das etwa so plausibel machen, dass man von einem ausgeglichenen Baum ausgeht. Dieses entspricht der Kodierung von 2N Wörtern mit gleichlangen Wörtern. Habe jetzt das Zeichen i eine Häufigkeit hi, die größer ist als die Summe der Häufigkeiten zweier anderer Zeichen j und k: hi>hj+hk, so lässt sich das erste Zeichen mit N-1 Bits kodieren, es rückt im Baum eine Ebene nach oben, während sich die anderen mit jeweils N+1 Bits kodieren lassen; sie sacken eine Ebene tiefer. Die Kodierung wird sich für das Zeichen i um hi Bits verringern, während sie sich für die Zeichen j und k um hj+hk Bits vergrößern wird; der Gewinn beträgt also hi-hj-hk Bits und ist somit positiv. Dieses Verfahren lässt sich jetzt verallgemeinert fortsetzen, und man kommt offenbar zu der Huffman-Kodierung, da die Zeichen mit der geringsten Häufigkeit immer tiefer sacken, solange die Summe ihrer Häufigkeiten noch kleiner ist als die eines einzelnen anderen Zeichens. Daraus folgt also, dass eine Huffman-Kodierung niemals schlechter ist als eine Kodierung mit gleichlangen Wörtern. Ein weiterer Vorteil ist, dass die Anzahl verschiedener Zeichen nicht länger von der Wortlänge abhängt, sondern beliebig gewählt werden kann. Man könnte also zu jeder Anwendung eine Kodierung konstruieren, die genau die von der jeweiligen Anwendung benötigten Zeichen festlegt.
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||