MPEG

MPEG steht f¸r "Moving Picture Coding Experts Group", die
1988 eingerichtet wurde, um einen Standard f¸r die Aufzeichnung von Video und Audio in
VHS-Qualit‰t auf CDs zu entwickeln (352 x 288 + CD-Audio bei 1,5 Mbits/sec).
MPEG verwendet zur Bildkodierung ein ‰hnliches Verfahren wie JPEG,
wobei zus‰tzlich ein B-Frame (bidirektional) eingef¸hrt wird. Dieser kann sich
Information sowohl aus bereits vorhandenen als auch aus sp‰teren I- oder P-Frames holen.
MPEG wird auch im Video-Recorder-Bereich eingesetzt, so dass Filme vor- und r¸ckw‰rts
sowie wahlfrei abgespielt werden kˆnnen.
Diese Site wurde kopiert von
http://www.rasip.fer.hr/research/compress/algorithms/adv/mpeg/index.html
MPEG
Purpose of this page is to give you quick look
on the MPEG standard, and to give some directions for you who decide to get
deeply into it.
MPEG is acronym for Moving Picture Expert Group, a group formed under ISO
(International Organization for Standardization) and the IEC (International
Electrotechnical Commission). Later, MPEG was given formal status within ISO/IEC.
The topics, which are covered in three parts of MPEG standard, are coding of
video and audio including synchronization of audio and video bitstreams with
multiple interleaved video sequences.
These three parts of the MPEG standard are:
Part 1: System aspects
Part 2: Video compression
Part 3: Audio compression
There are different types of MPEG. For example: MPEG-1, MPEG-2, MPEG-4 etc.
The most important differences between them are data rate and applications.
MPEG-1 has data rates on the order of 1.5 Mbit/s, MPEG-2 has 10 Mbit/s, and
MPEG-4 has the lowest data rate of 64 Kbit/s.
A video stream is a sequence of individual
frames. Every frame is a still image which shown together, one after another,
become a video motion picture. Usually at rate close to 30 frames per second.
Frames are digitized in a standard RGB format, 24 bits per pixel (8xRed,
8xGreen, 8xBlue).
MPEG algorithm operates on images represented in
YUV color space (Y Cr Cb). YUV format, also, represents images in 24 bits per
pixel (8 bits for the luminance information (Y-luminance provides a monochrome
picture) and 8 bits for each of two chrominance information (U and
V-chrominances provides the equivalent of color hue and saturation in the
picture)). YUV format can be more efficiently compressed than RGB. The YUV
format is subsampled. All luminance information is retained. However,
chrominance information is subsampled 2:1 in both, horizontal and vertical,
directions. Thus, there are 2 bits per pixel for any of U and V information.
This subsampling does not drastically affect quality because the eye is more
sensitive to luminance than to chrominance information. Subsampling is a lossy
step.
Video
Stream Data Hierarchy
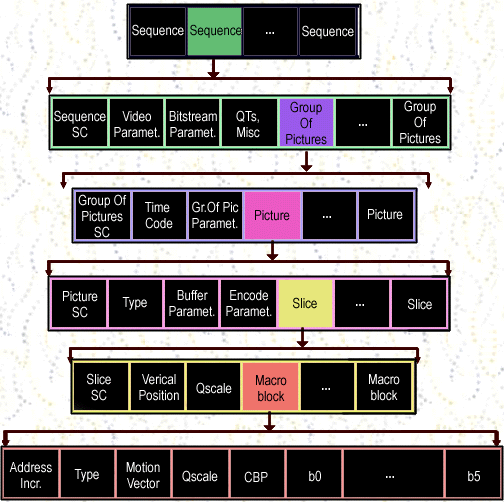
Video
sequence includes one or more
groups of pictures, begins with a sequence header and ends with an
end-of-sequence code.
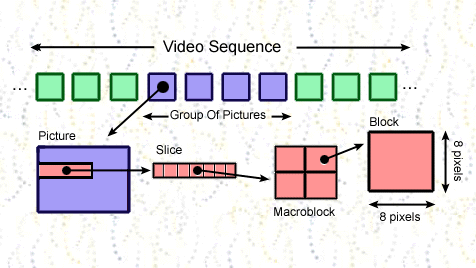
In MPEG, video stream breaks sequence of
images into a series of layers, each containing more precise sample clusters.
These layers are:
Group Of Pictures
is a header and a series of one of more pictures.
Picture
is primary coding unit of a video sequence. A picture consists of three
rectangular matrices representing luminance (Y) and two chrominance (Cb and Cr)
values. Being rectangular, the Y matrix has an even number of rows and columns.
The Cb and Cr matrices are one-half the size of the Y matrix in each direction
(horizontal and vertical).
Slice-MPEG
picture is composed of slices where each slice is sequence of macroblocks in
raster scan order.Slices can strech from one macroblock row to the next. This
slice structure, allows great flexibility in error handling and discovering
changes in coding parameters.
Macroblock
is basic coding block of an MPEG picture. It consists 16x16 sample array of
luminance (Y) samples together with 8x8 block of samples for each chrominances
(Cr and Cb). Y block consists of four 8x8 blocks of samples.
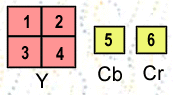
The most important aspect of MPEG is
similarity between two neighbour pictures.
There are three types of pictures that the
MPEG standard defines.
First are the Intra
Pictures (I-Pictures).

Intra Picture is encoded as a single image
using only information from that picture. I-Picture uses only transform coding,
so it provides low compression rate. In the most cases it uses cca two bits per
coded pixel.
Image blocks have very big spatial redundancy, so
MPEG tries to cut this huge amount of data.
The block is first transformed from the spatial
domain into a frequency domain using Discrete
Cosine Transform (DCT). DCT separates
the signal into independent frequency bands making data quantized. You can
imagine quantization like ignoring lower-order bits (just a little bit
complicated!!).
Quantization
is the only lossy part of the whole compression process other than subsampling.
Afterwards, the resulting data is run-length
encoded in a zig-zag
ordering to optimize compression. This zig-zag ordering produces longer runs of
zeros by taking advantage of the fact that there should be less high-frequency
information (more zeros as one zig-zags from the upper left corner towards the
lower right corner of the 8x8 block). Coefficient in the upper left corner of
the block, called the DC coefficient, is encoded relative to the DC coefficient
of the previous block (DCPM coding).
Second are
the forward
Predicted pictures (P-Pictures).
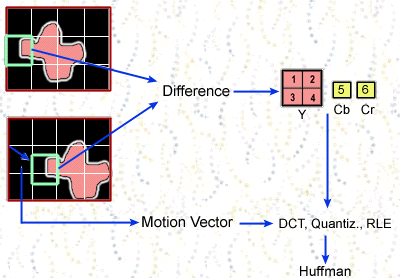
A P-Picture is nonintra picture. Nonintra
picture uses information which are displaced in time. P-Picture is coded with
reference to a previous image that could be either I or P Picture. Example
picture shows that the picture to be encoded is similar to the reference picture
except it is a little bit shifted.
Most of the changes between reference picture and
picture to be encoded can be represented as translation of small picture regions.
So technique that is used here is called motion
compensation prediction.
Each macroblock in a P-Picture can be encoded
either as an I-macroblock or as a P-macroblock. An I-macroblock is encoded just
like a macroblock in an I-frame. A P-macroblock is encoded as a 16x16 area of
the past reference picture, plus an error term (the difference between two
macroblocks).
A Motion
Vector is used to specify the 16x16
area of the reference frame. A motion vector (0, 0) means that the 16x16 area is
in the same position as the macroblock we are encoding. Other motion vectors are
relative to that position. There will be no perfect match for the macroblock in
the reference picture due to the spatial location, but the closest match is
searched. The error term is finally encoded using the DCT, quantization, and
run-length encoding.
Third are Bi-directional
predicted pictures (B-Pictures).
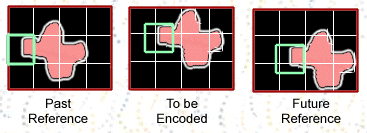
A B-Picture is also nonintra picture. It is
encoded relatively to the past reference picture, the future reference picture,
or both pictures. The future reference picture is the closest following
reference picture (I or P). The encoding for B-pictures is similar to P-pictures,
except that motion vectors may refer to areas in the future reference pictures.
For macroblocks that use both past and future reference pictures, the two 16x16
areas are averaged.